unbubble.eu/info/advanced-search Парсинг динамического контента
В этом году вебмастеры время даром не теряют, конкуренция всё растёт и растёт, кто-то трудился даже в праздники, а всё от того, что белые схемы хоть высокорентабельные и долгоиграющие, но и временной интервал развёртывания проектов довольно затяжной: от трёх месяцев и более, если сравнивать с теми же дорвеями. Но не так важно какие схемы использовать, ведь для всех них нужен уникальный контент и базы актуальных ключевых запросов. Где всё это достать, да ещё с минимальными расходами?
Вариаций на эту тему тысячи и одной ночи не хватит перечислить. Но универсальных методов единицы, один из них я опишу в этой статье. Он заключается в том, чтобы использовать лазейки которые имеются в поисковых системах (точнее в самой генерации поисковой выдачи), которые в последнее время очень активно стали противодействовать массовому наплыву запросов автоматических парсеров, скраперов и прочих роботов, которые ежесекундно буквально бомбят Google, Yahoo, Bing и т.д. Самый распространённый барьер — это ограничение запросов с одного IP-адреса методом капчи. Как известно, на всякое ограничение найдётся противодействие, в случае с CAPTCHA это онлайн-сервисы антикапчи, либо же смена IP-адреса при помощи proxy-адресов или VPN, но это дополнительные расходы.
Второй распространённый барьер — вёрстка выдачи контента на страницах поисковиков маскируется так, что самая востребованная часть контента теперь подгружается динамически при помощи различных скриптов, и в итоге методика копипаста тут не срабатывает, так как для отработки самих скриптов, требуется выполнение определённых действий: главным образом совершить клик по ссылке или произвести наведение курсора пользователем. Выход – эмуляция этих действий, чтобы спарсить динамический контент. Остановимся подробнее на обходе второго барьера.
Второй распространённый барьер — вёрстка выдачи контента на страницах поисковиков маскируется так, что самая востребованная часть контента теперь подгружается динамически при помощи различных скриптов, и в итоге методика копипаста тут не срабатывает, так как для отработки самих скриптов, требуется выполнение определённых действий: главным образом совершить клик по ссылке или произвести наведение курсора пользователем. Выход – эмуляция этих действий, чтобы спарсить динамический контент. Остановимся подробнее на обходе второго барьера.
Эта задача не так и неразрешима. Когда передо мной возник этот вопрос, я стала активно искать варианты в поиске, первое за что зацепилась — это то, что общение наших браузеров с серверами происходит при помощи POST и GET запросов. Практически можно сказать, что это нулевой уровень абстракции передачи данных в сети. Далее мелькнула мысль проверить, все ли известные парсеры способны нормально переваривать POST-запросы, также обязательным требованием была эмуляция действий пользователя и конечно же способность интерпретации сокрытых данных в формате JSON. Из трёх доступных в моём распоряжении были: Content Downloader – самый доступный и распространённый, как по цене так и в освоении, далее продвинутый ZennoPoster и профессиональный A-Parser. Цель была одна — взять произвольную поисковую систему и проверить, какой из них за один и тот же временной интервал способен максимально спарсить количество suggest-запросов (подсказок) с конкретного поисковика. Эксперимент расставил всё по своим местам.
Первый из списка бюджетный парсер был весьма неплох, он способен обрабатывать POST-запросы, но необходимо отлавливать их при помощи снифера, ещё из минусов то, что это десктопная версия, а это значит что скорость запросов напрямую зависит от моего Интернет-канала и его загруженности (как настроить парсинг в Content Downloader при помощи POST-запросов можно ознакомиться в этом видео).
ZennoPoster тоже с поставленной задачей справился, но были мелкие неприятности, это те же манипуляции с отловом запросов через Фиддлер-снифер. При попытке инсталляции самого программного модуля ZennoPoster на виртуальную операционную систему для увеличения скорости парсинга получить ощутимых преимуществ не получилось. Тайминги парсинга Зеннопостером не доминировали над Контент Даунлоадером, и причина тут одна: ZennoPoster Pro и Content Downloader максимально могут совершать парсинг в 50 потоков, поэтому как итог: дорого не значит быстро. Возможно, тут самим разработчикам в пору задуматься о выпуске 64-битных версий своих программ, так как у них тайминги в моменты пиковых нагрузок на процессоры по скорости исполнения значительно ниже своих 32-битных аналогов. Как настроить парсинг в ZennoPoster при помощи POST-запросов, можно узнать из этого видео.
Но вернемся к эксперименту и рассмотрим A-Parser. Разработчики предусмотрели версии как под Windows, так и под Linux, более того количество потоков от 100 и выше! И не смотря на то, что тоже отсутствует 64-битная версия под Windows, перечисленные качества с лихвой перекрывают этот недостаток. Теперь расскажу детально о самом эксперименте на примере парсера-победителя. Для испытаний мной был выбран экзотический поисковик, который многие обходят стороной, так как спарсить там что-либо нереально, потому что быстро банятся все лимиты. Поэтому обычный парсинг в данном случае не идёт, и нужно использовать пост-парсинг.
Поисковая система unbubble.eu хороша тем, что там уникальная выдача от Гугла по основным западным странам: немцы, французы, испанцы, голландцы, турки, поляки и англичане, также в заголовке Unbubble красуется надпись, что поиск 100% анонимный. При тщательном осмотре было выявлено, что если в настройках активировать опцию в 100 результатов, то за раз этот поисковик будет отдавать выдачу состоящую из 100 сниппетов. Это очень удобно, когда для парсинга контента используются сниппеты поисковиков. Основные операторы обозначены здесь: unbubble.eu/info/advanced-search
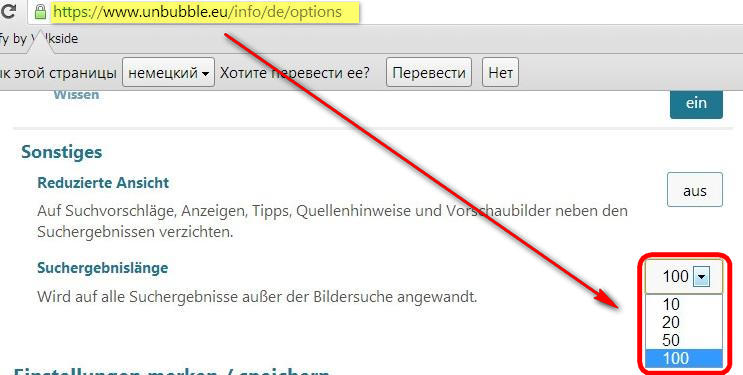
Unbubble, как и любой другой поисковик первого десятка, способен автоматически генерировать подсказки для популярных запросов. Поэтому тут все стандартно:
1. Нужно запустить любимый браузер, рекомендую Opera или Chrome (встроена консоль разработчика).
2. В строке поиска необходимо указать поисковую систему — unbubble.eu
3. После открытия домашней страницы поисковика в строке поиска нужно задать исходный запрос, например, Viagra.
4. Далее сочетанием горячих клавиш (Ctrl+Shift+I) открываем панель «Инструменты разработчика», где конкретно нас будет интересовать вкладка Network.
5. Теперь вернувшись в строку поиска, чтобы активировать подсказки, рядом с запросом вбиваем любой символ, можно даже пробел.
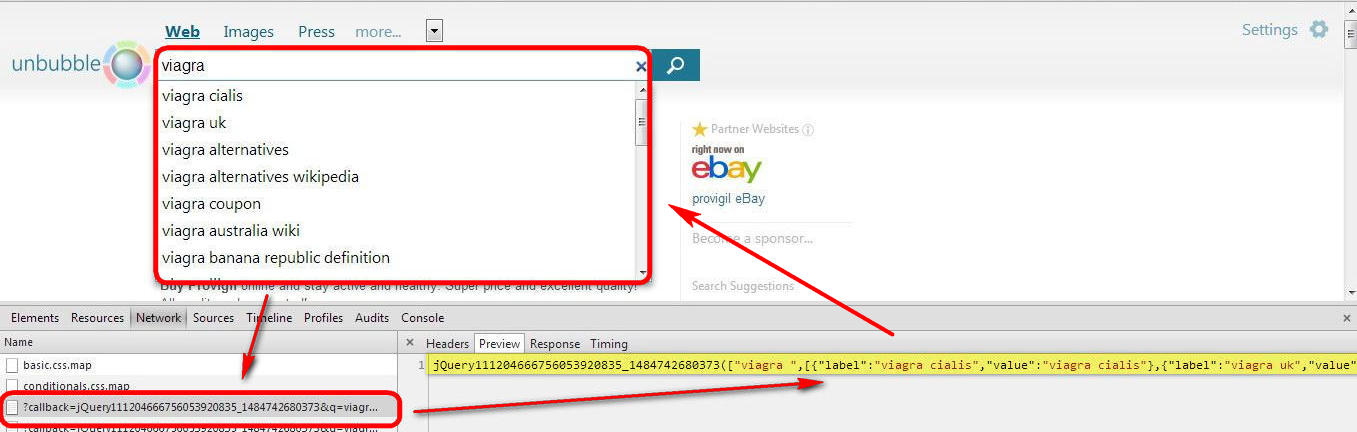
Обращаем внимание на произошедшие изменения в логах панели разработчика, а именно там появились отправленные запросы (слева), вызванные моими действиями, и ответ сервера (справа), который обработал браузер, чтобы визуально отобразились поисковые подсказки. Сам POST-запрос идёт на третьей позиции – это стандартный URL-адрес.
| https://suggest.unbubble.eu/?callback=jQuery111204666756053920835_1484742680373&q=viagra+&l=en-US&m=ac |
Поэтому если открыть его на новой вкладки браузера, то Unbubble ничего другого не остаётся, как показать искомый результат, который изначально скрыт за семью печатями и подгружается только динамически.

Далее вся рутина сводится к тому, чтобы полученную тарабарщину, представить в удобочитаемом виде, обработав её при помощи регулярных выражений и в итоге получить упорядоченный список поисковых подсказок. Запускаем A-Parser и делаем необходимые настройки, то есть создаем новый пресет:
- Открываем редактор заданий.
- Первым делом задаем тип парсера: Net:HTTP парсер стандартный модуль для парсинга HTML страниц.
- В строке – Формат результата прописываем своё регулярное выражение по причёсыванию поисковых подсказок от мусора и вырезанию их из J-son кода; значение в коде — % limit = 5; – указывает длину поисковой подсказки, то есть парсится будут все фразы состоящие до пяти слов включительно.
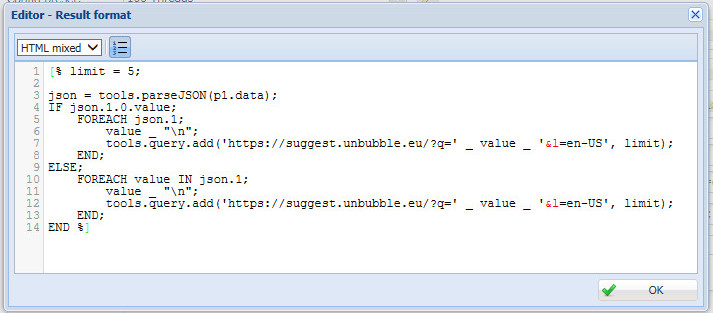
- В пункте – Запросы – два варианта: из текстового файла или небольшим списком, выбираем первый.
- Формат запроса – надо указать URL-адрес источника для парсинга, в нашем случае после обрезания всего лишнего получится вот такой:
| https://suggest.unbubble.eu/?q=$query&l=de-DE |
Где $query – переменная, которая будет принимать значения ключевых слов из файла.
de-DE — окончание, которое можно адаптировать под доступные версии локальной выдачи самого поисковика Unbubble: «de-DE» – Deutsch, «de-CH»- Deutsch (CH), «de-AT»- Deutsch (AT), «en-GB»- English, «en-US» — English (US), «fr-FR»- Français, «nl-NL»- Nederlands, «es-ES»- Español, «it-IT»- Italiano, «tr-TR»- Türk и «pl-PL» — Polski.
de-DE — окончание, которое можно адаптировать под доступные версии локальной выдачи самого поисковика Unbubble: «de-DE» – Deutsch, «de-CH»- Deutsch (CH), «de-AT»- Deutsch (AT), «en-GB»- English, «en-US» — English (US), «fr-FR»- Français, «nl-NL»- Nederlands, «es-ES»- Español, «it-IT»- Italiano, «tr-TR»- Türk и «pl-PL» — Polski.
- В пункте – Результаты – прописываем обычный формат вывода — $datefile.format().txt, то есть результат будет сохраняться в текстовом файле, в котором ключевые слова будут расположены в столбик.
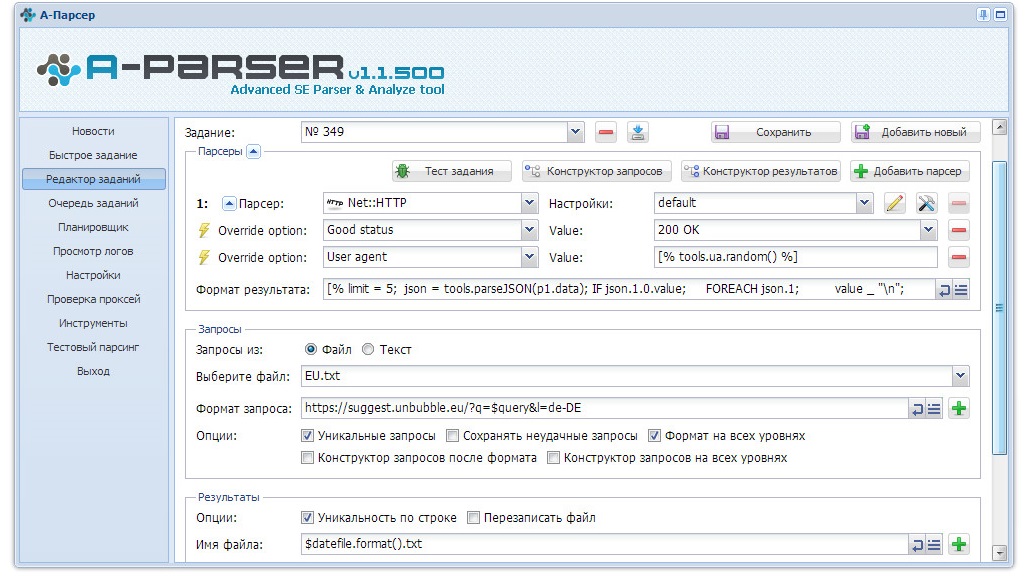
Созданный пресет можно сохранить в текстовом файле и затем с легкостью импортировать. Вот полный код пресета, его можете скачать по этой ссылке.
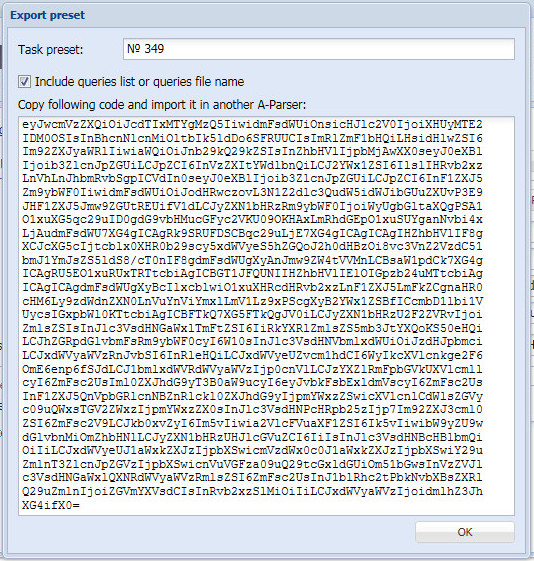
Показанный выше алгоритм POST-парсинга практически универсален и подойдёт для других поисковых систем:
Проблемы с которыми я столкнулась, могут возникнуть и у вас. Если используете русскую версию операционной системы, то браузер криво обрабатывает неродные символы алфавита, в частности характерные только для Германии, Франции, Италии и т.д. – языковых групп в алфавите которых присутствует умлаут-символика, например типичные для немецкого языка: ä, ö, ü, Ä, Ö, Ü, ß, è, é, û. Тут можно пойти двумя путями: попробовать в региональных настройках самой операционной системы дополнительно активировать нужную языковую группу, либо же поступать как я, после завершения процесса парсинга производить поиск/замену, например, имеем запрос такого вида:
viagra \u00f6sterreich bestellen — должен быть — viagra österreich bestellen
Значит символы \u00f6 необходимо массово заменить на символ – ö и т.д. Вот шпаргалка для немецких умляутов:
‘\u00a0’ => ‘ ‘,
‘\u003c’ => ‘<‘,
‘\u003e’ => ‘>’,
‘\u00e4’ => ‘ä’,
‘\u00c4’ => ‘Ä’,
‘\u00f6’ => ‘ö’,
‘\u00d6’ => ‘Ö’,
‘\u00fc’ => ‘ü’,
‘\u00dc’ => ‘Ü’,
‘\u00df’ => ‘ß’,
‘\u20ac’ => ‘€’,
‘\u00a3’ => ‘£’,
Желаю вам успехов в динамическом парсинге!
Автор статьи: Alisa.


Comments
Post a Comment